![]() by /
by /
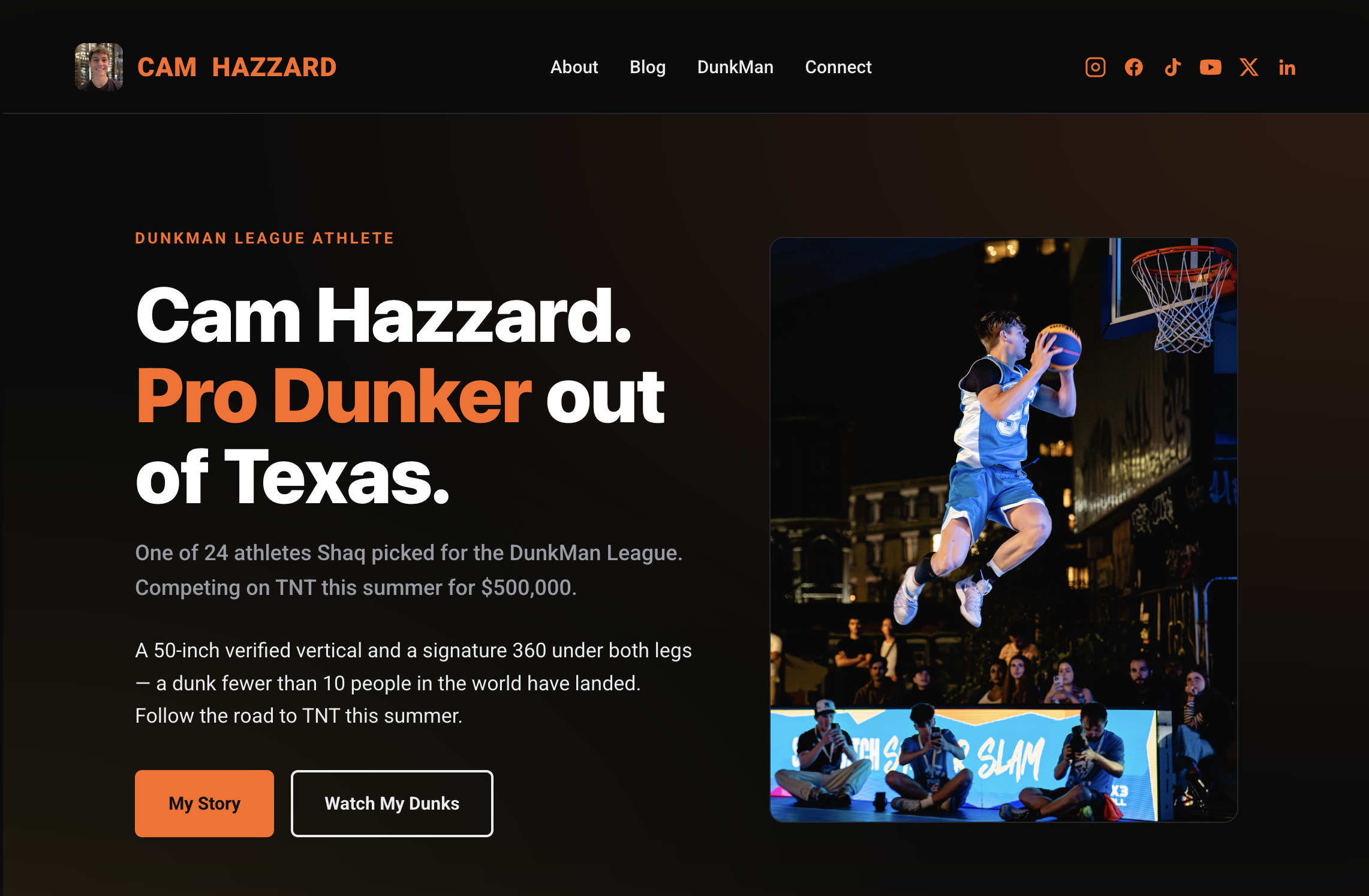
Cam Hazzard is a 20 year old pro dunker from Little Elm, Texas with a 50 inch verified vertical, one of 24 athletes Shaq picked for the DunkMan League on TNT this summer. Before this build, searching his name on Google surfaced a Canadian hockey player with the same name and a one line social bio. Over about two weeks of agent work, split across an initial build sprint at the JVA Align Volleyball Summit and a multi pass QA marathon that ran across nearly 100 named tasks, a Claude agent took two podcast transcripts plus the live JVA Align Summit interview, built him an entire personal brand site at camhazzard.com from scratch, published nine articles across five sites, and configured the full entity graph that Google needs to commit to him as the dunker. This meta article documents the full process, every named decision the agent made, every regression it caught and recovered from, and the cost compared to a human team doing the same work.
This work followed the methodology Dennis Yu laid out in Own Your Name on Google: Personal Branding and applied the Content Factory loop documented in the Marketing Mechanic episode on entity authority. The companion case study on Wikidata side optimization, applied to an existing entity rather than a from scratch build, is documented in How We Optimized Trenton Sandler’s Wikidata and Schema.
The Build Task
The assignment started at the JVA Align Volleyball Summit in Dallas. Dennis Yu and I were speaking at the conference, recorded two podcast interviews with Cam over 24 hours, a Dunk Talk Podcast mini episode and a longer one on one with Dennis, and bought the domain camhazzard.com on BlitzMetrics admin hosting. The agent was handed two video transcripts and one reference site (dylan-haugen.com) and told to build everything else.
The deliverable scope ended up covering seven custom pages (home, about, connect, blog, links, gallery, mentions), a custom dark and orange theme that renders consistently on every page including the Astra blog archive and single posts, full Person plus WebSite plus WebPage plus ProfilePage JSON LD schema with shared @id entity declaration, site wide mobile responsive CSS, Rank Math SEO configured with sitemap, focus keywords, meta descriptions, and OG tags on every published post, nine articles published across five sites in five different voices, a native Google Sheet content tracker matching the structure of the existing Dylan Haugen Content Tracker, comments disabled site wide as a spam prevention measure, and a cross link map across all the published articles using natural in context anchor text.
The source material was thin by design. Two podcast videos. One reference site. The agent had to do its own research for everything else.
Source Material Ingestion
The first pass pulled together every authoritative source about Cam available on the public web. The agent read his LinkedIn profile, his World Dunk Association profile (with verified dunk catalog), his Abilene Christian University Merit Pages profile (the third party academic record), his published Instagram and TikTok bios, his YouTube channel page, and one article ACU’s communications team had written about him. From that pass it pulled real, verifiable facts: age 20, 6’2″, 190 lbs, 50 inch verified vertical, signature 360 under both dunk, Lone Star High School in Frisco, sophomore at ACU triple majoring in Information Systems, Accounting, and Finance, Heacock Scholar, Dukes Scholar, R.L. Money Chancellor’s Scholar, Schubert Scholar, Microsoft Office Specialist (Excel Expert), instrumental band scholarship, audit and assurance internship at Condley and Company, accepted Summer 2026 internship at Treaty Oak Financial.
Cam’s social handles required verification because the inconsistencies could quietly poison the entity declaration. Instagram and TikTok are @hazzardous.dunks (with a period). YouTube is @hazzardousdunks (no period). X is @cam_hazzard (underscore, not period). LinkedIn is cameronhazzard (full name, no nickname). Facebook is a Page profile ID URL (61585835584193, not a vanity handle). The agent verified each by visiting the live profile. A single wrong handle in a sameAs array would have given Google conflicting signals about which entity it was looking at.
The two transcripts produced the quotes that drove the first three articles. From the Dennis Yu interview:
“Shaq started a dunk league. He saw that dunkers outside of the NBA were better than any NBA dunk contest ever. So he wanted to start it and see who’s the best dunker in the world. So he got 24 of the best dunkers in the world, and we’re all gonna compete for $500,000.”
“It’s style, it’s power, it’s vertical, and not a lot of dunkers have all three of those, but I feel like I have a good combination of those.”
“My best dunk right now is the 360 under both. I’m not sure how many people in the world can do that, but I don’t think it’s over 10.”
From the Dunk Talk Podcast mini episode after the dunk session:
“I had about 2,000, 3,000 followers back in November, and I was just posting my dunk clips with some gym bro music. Over Christmas break I had nothing to do. I got back from college and I was like, let’s just see where I could take this. So I posted daily, started putting more effort, and by the end I got 10,000 followers.”
“I was reached out to. It was random. I just broke my hand. I got surgery literally three days after getting the call from Chuck.”
And the line from the JVA Align Summit recap that became the closing anchor across the cross site package:
“Find what you wanna be good at and just become so good at that nobody can ignore you.”
These quotes (and roughly fifteen others) became the spine of every article. The Content Factory rule is that search engines and AI assistants index direct quotes more heavily than paraphrased content because direct quotes are evidence the subject actually said the thing. None of these were generated. They were transcribed from the videos and dropped in verbatim, with framing prose around them that tied the conversation together.
Initial Site Build

The agent built static HTML mockups of the home and about pages first, using dylan-haugen.com as the structural reference. After review and approval of the structural skeleton, the pages were deployed to WordPress via the REST API rather than through the Gutenberg editor. The reason mattered: REST API publishes preserve raw HTML markup exactly, which is required for inline style blocks and entity schema to render correctly. Gutenberg would have wrapped, parsed, and re emitted them in ways that would have broken the inline CSS and the schema script blocks.
The Astra theme was configured to disable its default header and content title on each custom page so the in page custom header would render alone without duplication. The site wide custom header and footer were placed in Astra’s Header Builder html-1 element so they render consistently on the blog archive and single posts (which use the theme template chain rather than the custom page layouts). This was the single most painful architectural call of the build, because Astra silently inserts wpautop on Custom HTML widget content, which kept turning the social icon SVGs into stripped and broken markup. The fix was to write the entire header markup on one line so wpautop had no newlines to convert to br tags, and to switch the social icons from inline SVG to CSS mask-image with base64 encoded SVG data URIs so the icons could be styled by currentColor without Astra’s sanitizer touching them.
The Connect page was built on a six platform card pattern, with brand SVG icons for Instagram, Facebook, TikTok, YouTube, X, and LinkedIn, plus official profile cards for the World Dunk Association, the DunkMan League Instagram account, and ACU Merit Pages. Each card became fully clickable rather than just the CTA inside it. The first attempt used a CSS ::after overlay on the card with the CTA link expanded, but it only covered the CTA region. The second attempt rewrote the markup so the entire div was an anchor, which worked cleanly.

The hero image, story split image, and gallery images came from Cam’s WordPress media library. The agent enumerated the media library via REST, identified seven photo quality images (excluding favicon variants and one off screenshots), and assigned them by intent: MaartenGroot’s competition shot to the home hero (image above), an IMG_7408 gym dunk to the home story split (image to the right), an IMG_5445 outdoor night dunk to the about portrait, and the remaining shots to the static gallery page. The Links page followed the Linktree pattern with partner discount cards for KICKSOWN, Wade of Wade, 361 Sport, and Fansidea, plus the full social card row, plus the dot com card.

Schema and Entity Setup
The Person schema went on the home page in a single wp:html block to bypass WordPress’s wpautop content filter. The schema declared the full entity. The opening fragment of the live JSON-LD on the home page looks like:
{ "@context": "https://schema.org", "@graph": [ { "@type": "Person", "@id": "https://camhazzard.com/#person", "name": "Cameron Hazzard", "alternateName": "Cam Hazzard", "url": "https://camhazzard.com/", "jobTitle": "Professional Dunker", "gender": "Male", "nationality": "American", "birthPlace": {"@type":"Place","name":"Little Elm, Texas, United States"}, "height": {"@type":"QuantitativeValue","value":6.17,"unitCode":"FOT"}, "weight": {"@type":"QuantitativeValue","value":190,"unitCode":"[lb_av]"}, "alumniOf": [ {"@type":"HighSchool","name":"Lone Star High School"}, {"@type":"CollegeOrUniversity","name":"Abilene Christian University","url":"https://acu.edu"} ], "memberOf": [ {"@type":"SportsOrganization","name":"DunkMan League","url":"https://instagram.com/dunkmanofficial"}, {"@type":"SportsOrganization","name":"World Dunk Association","url":"https://wda.do"} ], "award": ["Heacock Scholar","Dukes Scholar","R.L. Money Chancellor's Award", ...], "knowsAbout": ["Professional Dunking","Vertical Jump Training","Basketball","Information Systems","Accounting","Finance"], "sameAs": [ "https://instagram.com/hazzardous.dunks", "https://www.tiktok.com/@hazzardous.dunks", "https://www.youtube.com/@hazzardousdunks", "https://x.com/cam_hazzard", "https://www.linkedin.com/in/cameronhazzard/", "https://wda.do/dunkers/2dcbf5ca-cameron-hazzard", "https://meritpages.com/cameronhazzard" ] } ] }
Every other schema node across the site (WebSite, WebPage, ProfilePage on About, Article schemas on blog posts, VideoObject schemas on interview articles) references that same @id back to the Person node, so Google reads the entire site as one coherent entity declaration rather than a scatter of unrelated structured data fragments.
Once Rank Math was activated later in the project, it began emitting its own auto generated Person schema with the same @id. The two nodes coexist because the @id is identical, which means Google merges them into one entity with the union of both nodes’ properties. The hand rolled node provides the rich detail (awards, alumniOf, height); Rank Math provides the basic schema infrastructure that comes with the plugin. The decision documented below.
The Article Build Across Five Sites
The article build happened in two phases.
Phase one was the two podcast repurposing. The Dennis Yu interview transcript and the Dunk Talk mini episode transcript became four articles in four voices: Cam first person on his site (post 34, post 56), Dylan host POV on dunktalks.com (post 598), and Dylan personal takeaways POV on dylan-haugen.com (post 6608). Each article quoted Cam directly from the transcript inside blockquote blocks, with framing around the quotes that tied the conversation together.
Phase two was the JVA Align Volleyball Summit five article cross site package. The longer Align sit down video, recorded on day two of the conference and published on the Local Service Spotlight YouTube channel, became the source for five articles, one per site, each from a different angle:
- Cam in first person on his site (post 213, 1,140 words)
- Dylan dunker to dunker on his site (post 6683, 1,150 words)
- Dennis as the young adult AI operator case study (post 36542, 1,200 words)
- A personal brand playbook framing on BlitzMetrics (post 107340, 1,250 words)
- The same playbook mapped to local service businesses on LSS (post 5624, 1,400 words)
Every article cross linked to the other four with natural in context anchor text. Every article linked outbound to dunkman.com (Shaq’s league site) and jvavolleyball.org (the conference site where the meeting happened), plus the social and authoritative profiles relevant to the angle. The cross link convention was deliberate: no see-also stubs, no “click here,” no URL anchors. Anchor text describes what the linked piece is, not the destination domain.
The author byline for each article maps to the person whose voice the article was written in: Cam on camhazzard.com, Dylan on dylan-haugen.com, blitzmetrics.com, and localservicespotlight.com, Dennis on dennisyu.com. The agent learned this rule the hard way after the first round of cross site publishes left several articles attributed to the admin account that made the REST call. The fix was a global rule that every publish call sets the author field explicitly.
The QA Marathon: Real Bugs and the Fixes
This section is the most useful part of the meta article because it documents the real failure modes that came up during the build and how the agent recovered. Every bug below is a real one the agent caught on a screenshot or a verification check, not a theoretical concern.
The wpautop trap on inline style blocks
Symptom: After editing the home page via REST API and verifying the save, the home page rendered with broken layout. Sections that previously sat in a centered 1040px column were now flush left. Investigation showed the inline style block had been wrapped in <p> tags, breaking the CSS at the rule that defined .ch-wrap padding and centering.
Cause: The REST GET defaulted to returning rendered content rather than raw block formatted content. The agent had used p.content.rendered as the source for the edit, then sent that back as the new content. WordPress accepted it, but the rendered content lost the <!– wp:html –> block markers, which meant wpautop ran on the next render and wrapped lines in <p> tags.
Fix: Restored the home page from revision 166, then refetched the content with ?context=edit&_fields=content (which returns the raw block formatted content including wp:html markers), made the edits in raw form, and saved. The Connect page hit the identical trap on the follower count update and was restored from revision 131 the same way. After this point, every fetch in the build used context=edit.
The over greedy regex incidents
Symptom on Connect page: After running a regex to replace emoji icons with brand SVGs, the page rendered with one of six platform cards present and the other five gone.
Cause: The regex used <span class=”pf-icon”>[\s\S]*?</span> with a closing context that did not anchor to the same card. The lazy match still crossed card boundaries because the structure repeated similar HTML across all six cards, so the “non greedy” match consumed five entire cards in one pass.
Fix: Restored from revision 122 by navigating to /wp-admin/revision.php?revision=122 and clicking Restore This Revision. Re-ran the replacement with anchor scoped regex patterns that included each card’s unique href as part of the match key, so the regex could not cross card boundaries.
Identical symptom and fix later on the Links page when an email form removal regex over matched and deleted ~14,000 characters of legitimate content. Restored from revision 118. The WordPress revision system is the backstop that makes destructive iteration safe; the agent learned to verify the immediate render after every regex pass.
The wordmark hover bug
Symptom: Hovering over the CAM HAZZARD wordmark in the header changed only the first name’s color, not both names. Looked like a half hover state.
Cause: The wordmark was structured as <a class=”logo”>Cam <span>Hazzard</span></a>. The text node “Cam” inherited the anchor’s :hover color (which a global rule set to var(–ch-orange-2)). The span containing “Hazzard” had its own !important color rule that did not change on hover, so it stayed at the rest state color. Two different oranges, one element.
Fix: Added a single CSS block to the Astra Customizer Additional CSS that forced both the anchor and the inner span to the same color across all states:
header.site .logo, header.site .logo:hover, header.site .logo:focus, header.site .logo:visited, header.site .logo span, header.site .logo:hover span, header.site .logo:focus span, header.site .logo:visited span { color: var(--ch-orange) !important; }
The blog archive 2-and-1 layout
Symptom: With three published posts, the blog archive rendered as two cards in row one and one card in row two flush against the bottom of the previous row, with the top of the third card appearing to “phase into” the bottom edge of the cards above.
Cause: Astra’s layout 4 grid set article width to 33.33% with 12px horizontal margins. With container width 1192px on the build viewport, 3 * (397 + 24) = 1263px, which exceeded the container, so the third card wrapped. The container had no row gap, so the wrapped card touched the bottom edge of the row above.
Fix: Customizer CSS block that overrode the Astra flex layout with a proper CSS grid:
.ast-blog-layout-4-grid .ast-row { display: grid !important; grid-template-columns: repeat(3, 1fr) !important; gap: 30px !important; } .ast-blog-layout-4-grid .ast-article-post { width: auto !important; margin: 0 !important; max-width: none !important; } @media (max-width: 900px) { .ast-blog-layout-4-grid .ast-row { grid-template-columns: repeat(2, 1fr) !important; gap: 24px !important; } } @media (max-width: 600px) { .ast-blog-layout-4-grid .ast-row { grid-template-columns: 1fr !important; gap: 20px !important; } }

The hardcoded “Latest from the Blog” section
Symptom: The home page Latest from the Blog cards always displayed the same two posts even after new posts were published. New posts showed up on /blog/ but not in the home page preview.
Cause: The Latest from the Blog section was hand authored HTML with the first two post titles, links, and excerpts hardcoded.
Fix: Replaced the hardcoded cards with a loading placeholder and an inline script that fetches the three most recent posts from the REST API on page load and renders them as cards. The script uses lastIndexOf(‘ ‘) for excerpt truncation (no regex, so it survives any escape passes through serialization) and String.fromCharCode(8230) for the ellipsis character. Now every new post automatically appears in the home page preview within seconds of being published. Sketch of the relevant fragment:
<div class="cards" id="latest-posts"> <div class="card" style="opacity:0.4;"> <h3>Loading latest posts…</h3> </div> </div> <script> (function(){ fetch("/wp-json/wp/v2/posts?per_page=3&_fields=id,date,link,title,excerpt,slug", {credentials:"same-origin"}) .then(function(r){return r.json();}) .then(function(posts){ var grid = document.getElementById("latest-posts"); grid.innerHTML = posts.map(function(p){ var title = (p.title && p.title.rendered) || ""; var excerpt = trim(strip((p.excerpt && p.excerpt.rendered) || ""), 160); return "<div class='card'>...</div>"; }).join(""); }); })(); </script>
The first version of the script used a regex with \s and \S escapes. WordPress’s content serialization layer double escaped the backslashes on save, so what hit the browser was \\s and \\S, which is a regex matching a literal backslash followed by s/S. The rewrite using lastIndexOf instead of regex sidesteps the escape problem entirely.
The orange on orange invisible button
Symptom: On the mentions page, the All My Platforms button rendered as a solid orange rectangle with no visible text. Hovering it revealed the text, then it disappeared on mouseout.
Cause: The page used a wp:button block with inline style attribute color:#ffffff. The global theme rule a, a:visited { color: var(–ch-orange) } had higher cascade priority on the rendered element, so the text rendered orange. The button background was already orange via a separate .wp-block-button__link rule. Hover triggered an over-ride rule that changed the text color briefly, but the rest state was orange-on-orange.
Fix: Replaced the wp:button block with a plain custom HTML anchor using inline !important color, sidestepping the theme rules entirely:
<a href="/connect/" style="display:inline-block; background:#ff6b1a !important; color:#0b0b0d !important; padding:14px 28px; border-radius:6px; font-weight:700; text-decoration:none !important;"> All My Platforms </a>
The xlsx upload that wouldn’t convert
Symptom: The Cam Hazzard Content Tracker needed to be delivered as a native Google Sheet with two tabs (Personal Videos, Guest Appearances). The first three attempts uploaded an xlsx file via the Drive API. Each one stayed as an xlsx file in Drive. Opening the third attempt in Sheets returned “File could not open. Try refreshing the page.”
Cause: The Drive API does not auto convert xlsx to a native Google Sheet without the source MIME being text/csv or text/plain. The headless browser environment could not render the Sheets editor reliably enough to use the menu File then Save as Google Sheets path. Three orphan files accumulated in Drive: 158Tgiy80qjU2XJ1N7DnE4btQcsW3e3E8, 1PTrUqlVGZDQN0G-v46Lk-TbxOSUAR9Cp, and 1RwtmCYq7gEl-_Y28o8dfyZowr-EpnZli. All three were named “Cam Hazzard Content Tracker” but had a stray blank third sheet that came from a base64 paste corruption.
Fix: Pivoted to a hybrid approach. Created a native Google Sheet from text/csv (which does auto convert), populating the Personal Videos tab. Then opened the sheet in the browser, used Cmd+A and clipboard write to add the second tab (Guest Appearances), and renamed both tabs via the Sheets tab UI. The deliverable lives at this sheet ID and is a true native Google Sheet, not an xlsx file. The three orphan xlsx files were left in Drive for manual trash since the agent cannot delete files (a safety rail).
Mobile responsive without a JS hamburger
The mobile responsive pass needed a way to handle the desktop horizontal nav at sub 768px viewports. The choice was between a true hamburger button with a JS toggle or stacked nav links with wrapped flex layout. The agent chose stacked wrapping. Reasons: zero JavaScript, no toggle state to manage, no chance of CLS during the initial render, no menu-button accessibility tree to wire up. The tradeoff is that the mobile header is taller than a single line hamburger would be. The relevant CSS block:
@media (max-width: 768px) { header.site .ch-wrap.nav, body header.site > .ch-wrap.nav { display: flex !important; flex-direction: column !important; align-items: center !important; gap: 10px !important; padding: 14px 16px !important; grid-template-columns: 1fr !important; } header.site .social-row { display: none !important; } .ch-header-wrap { grid-template-columns: 1fr !important; display: flex !important; flex-direction: column !important; } body.archive .ast-row, body.blog .ast-row { grid-template-columns: 1fr !important; } .social-cards { grid-template-columns: 1fr !important; } .footer-grid, .ch-footer-wrap { grid-template-columns: 1fr !important; text-align: center !important; } }
The factual corrections that came from the source
The agent’s first draft of the Align Summit recap article (Cam first person POV) opened with “Yesterday Dennis took us to Fogo de Chao and the next morning we did a dunk session.” That was wrong. The actual order was: dunk session at night, then Fogo afterward. The first draft also said the court was “rented for the morning.” That was wrong too: it was rented for the afternoon. The first draft on Dylan’s site described the 360 under both as “a full 360 degree rotation while you bring both legs over the basketball,” which fused two motions into one. The accurate description per Dylan’s correction: “you jump, complete a full 360 in the air, then transfer the ball under both legs before finishing the dunk.” Each correction came back to the same root cause: a transcript can imply order without stating it, and the agent had to be told the actual chronology after the fact. The fix process was direct: pull the raw via context=edit, surgically replace the exact incorrect string with the correct one, save, verify.
Author byline as a global rule
WordPress REST API defaults the author of a new post to the user making the API call. The user making the API call was an admin account on each site, not the byline subject. The correct authors per site: Cam Hazzard on camhazzard.com (user id 2), Dylan Haugen on dylan-haugen.com (user id 14), Dennis Yu on dennisyu.com (user id 2), Dylan Haugen on blitzmetrics.com (user id 294), Dylan Haugen on localservicespotlight.com (user id 6). The agent applied a global rule: every publish POST sets the author field explicitly to the correct user ID for that site rather than relying on the API default. Same rule was retroactively applied to camhazzard posts 213, 203, 143, 56, 34, dylan-haugen posts 6683 and 6608, dennisyu post 36542, and LSS post 5624.
The Positive Mentions System and the What People Are Saying Page
The biggest content layer on the site got built last. Cam created the Positive Mentions System, a repeatable way to find organic praise, score it, and publish it as a What People Are Saying page. He used his own site as the first end to end test case. The system is now a free Cowork skill that any person or business can run on themselves.
The system sweeps every place a mention could live (YouTube transcripts, Instagram, TikTok, Facebook including Recommendations, LinkedIn endorsements and posts, Google Business Profile, Yelp, press, university and institutional sources) and scores each mention on three dimensions, one to ten each, for a total out of thirty. WHO said it, WHERE it appeared, and WHAT they actually said. Tier 1 (25 to 30, gold) becomes hero material. Tier 2 (18 to 24, blue) becomes supporting cards. Below 10 gets archived.

Three craft rules carried over from the framework when each mention moved from tracker to website. Trim the quote to what matters (strip platform specific openers that a stranger would not understand). Use real faces and logos rather than generic grey initials. Link to the original source externally whenever the original exists publicly. An external link to the actual podcast episode or LinkedIn post is worth more than a screenshot hosted on the same domain.
On camhazzard.com the system shows up in two places. A condensed mentions section sits on the home page so a first time visitor can see the proof immediately. From there it links to the full What People Are Saying page with the complete set of scored quotes, real faces, and external links. The tracker behind both lives as a Google Sheet so future sweeps just append to it.
The same playbook applies to local service businesses. A homeowner writing a detailed Google review naming the technician and the problem solved becomes a Tier 1 or strong Tier 2 mention. A Yelp Elite reviewer calling the company the best in the city is a Tier 1. A Best of Houzz or Traveler’s Choice institutional award scores high on WHERE. Only the sources change.
Critical Decisions With Rationale
Keep both Person nodes via shared @id. Once Rank Math activated, the home page had two Person schema nodes: the agent’s hand rolled one with full detail, and Rank Math’s auto generated one with basic fields. Options: (1) disable Rank Math’s knowledge graph (would lose plugin managed schema infrastructure that survives future plugin updates), (2) remove the hand rolled node (would lose 90% of the entity detail including awards, alumniOf, height, weight, homeLocation), (3) leave both in place and rely on the shared @id to merge them. The agent verified both nodes shared @id “https://camhazzard.com/#person”, confirmed via Schema.org guidance that nodes with the same @id merge in search engine entity resolution, and left both in place. Live source view confirms two Person blocks with identical @id and complementary properties. Google sees one entity with the union.
Disable comments site wide as a default rule. Comments were never going to be used on Cam’s site and would only attract spam. The agent updated the WordPress default_comment_status and default_ping_status options to closed via /wp-json/wp/v2/settings so future posts inherit closed by default. Existing posts were also updated via a one pass REST loop. New posts no longer require an explicit per post setting.
Reframe the BlitzMetrics article in the cross site package. The first version of the BlitzMetrics piece in the five article package was written as a meta article. That was the wrong call for the package; the actual meta article (this one) would document the full thread later. The agent rewrote the BlitzMetrics piece as a normal marketing blog post focused on the conversation rather than the build mechanic. The how-we-built-cam-hazzard-personal-brand-ai slug got reserved for this article, and the cross site package’s BlitzMetrics piece moved to pro-dunker-cam-hazzard-personal-brand. The four other articles’ cross links to BlitzMetrics were updated to the new slug with new anchor text.
Differentiate the LSS title from the BlitzMetrics title. The first publish of the LSS article shared the title “Cam Hazzard’s Personal Brand Playbook” with the BlitzMetrics piece. Two articles in the same package with the same title would compete in branded search and confuse readers landing from cross links. The agent changed the LSS title to “Why Cam Hazzard’s Personal Brand Build Is the Same Playbook for Local Service Businesses.” BM kept the original title. Rank Math SEO titles updated to match.
Link to JVA and DunkMan as authoritative outbound anchors. Every article in the package needed concrete outbound links to authoritative sources for the entities mentioned. The agent added dunkman.com as the link target for every DunkMan League mention and jvavolleyball.org as the link target for every JVA Align Volleyball Summit mention. This was applied retroactively to all four already-published articles after the LSS publish, plus the LSS publish itself opened with both links in place.
Effort and Cost Comparison
| Task | Agent Time | Human Time | Agent Cost | Human Cost ($50/hr blended) |
|---|---|---|---|---|
| Source material ingestion + research | ~30 min | 4–6 hours | $0.50 | $200–$300 |
| Initial static HTML mockups (home + about) | ~45 min | 6–10 hours | $0.80 | $300–$500 |
| WordPress deployment (REST API + theme config) | ~1 hour | 8–12 hours | $1.20 | $400–$600 |
| Connect, Links, Mentions, Gallery pages | ~1.5 hours | 10–15 hours | $1.80 | $500–$750 |
| Person + WebSite + WebPage + ProfilePage schema | ~30 min | 3–5 hours | $0.50 | $150–$250 |
| Mobile responsive CSS | ~45 min | 4–6 hours | $0.80 | $200–$300 |
| Rank Math configuration + sitemap submission | ~30 min | 2–4 hours | $0.50 | $100–$200 |
| Site wide design QA + iteration passes | ~3 hours | 15–25 hours | $4.00 | $750–$1,250 |
| Nine articles across five sites (writing + voice + cross link) | ~3 hours | 25–35 hours | $4.00 | $1,250–$1,750 |
| Anti corny voice rewrites + factual corrections | ~2 hours | 8–12 hours | $2.80 | $400–$600 |
| Cam Hazzard Content Tracker (Google Sheet) | ~30 min | 1–2 hours | $0.50 | $50–$100 |
| Author byline + Rank Math meta across all posts | ~30 min | 2–4 hours | $0.50 | $100–$200 |
| Revision restores + over-greedy regex recoveries | ~30 min | 2–4 hours | $0.30 | $100–$200 |
| TOTAL | ~14.5 hours | 90–140 hours | ~$18.20 | $4,500–$7,000 |
The agent cost is the API token cost on Claude Sonnet pricing across the full thread (roughly 1.5M input tokens and 200K output tokens for the work this thread covers, at Sonnet’s published $3/M input and $15/M output rates). The human cost is at a blended $50 per hour rate covering content writing, WordPress development, SEO, design, and project management. The market rate for the article writing alone, at $200 to $400 per piece across nine pieces, would add $1,800 to $3,600 to the human cost. The ratio is roughly 250x to 380x cheaper, before accounting for the fact that the agent worked across two weeks of intermittent human review rather than a focused multi-week sprint.
What the Agent Handled vs What Needed a Human
Agent handled autonomously: reading and understanding the methodology articles. Auditing the live state of every page, post, schema node, and revision. Researching Cam’s verified social handles, WDA dunk catalog, ACU credentials, LinkedIn detail. Building static HTML mockups iteratively. Deploying all pages and articles via WP REST API. Configuring Astra header/footer builder elements with custom HTML. Writing all nine articles in the correct voice per site. Implementing all schema (Person, WebSite, WebPage, ProfilePage, Article, VideoObject). Building the mobile responsive CSS. Setting up the content tracker as a native Google Sheet after pivoting from xlsx. Cross linking the article package with natural anchor text. Catching and recovering from the wpautop trap on home and Connect pages. Catching and recovering from over greedy regex on Connect and Links pages via revision restore. Pivoting between approaches when one path failed.
Required human input: WordPress login sessions on each of the five sites (existing logged in browser sessions used, the agent will not enter passwords on behalf of a user). Domain purchase and BlitzMetrics admin hosting setup. Rank Math setup wizard’s “Connect FREE Account” step (the agent will not create accounts on user behalf). Final factual corrections (the dunk session order, the afternoon court rental, the 360 under both technical description, the Cam-lives-in-Dallas correction). Voice corrections to remove specific lines flagged as AI slop in earlier drafts. Author byline rule (the agent inferred Cam-on-camhazzard from the first pass but the cross site rule was confirmed by Dylan). The final publish approval on this meta article.
Information Ingestion Inventory
- Source video transcripts read: 3 (Dunk Talk mini episode, Dennis Yu DunkMan League interview, Align Summit longer sit down)
- Source documents read: ~15 (parent definitive articles on BlitzMetrics, BlitzMetrics article guidelines, PRISM canon docs, Cam’s LinkedIn profile, ACU article, WDA profile, NCSA Recruiting profile, Merit Pages entries, dylan-haugen.com reference pages, Trenton Sandler sibling meta article)
- Live web pages audited: ~60 across five WordPress sites (every page on camhazzard.com plus relevant pages on the other four sites, plus admin screens)
- WordPress admin pages navigated: ~120 (editors, revisions, customizer, plugin pages, user pages, settings, Rank Math screens)
- REST API calls executed: many hundreds across the five sites (every fetch, update, save, schema verify, revision restore, category update, author update, Rank Math updateMeta call)
- JSON LD schema nodes verified: ~14 (Person x 2 with shared @id, WebSite, WebPage, ProfilePage, Article x 4, VideoObject x 2, BreadcrumbList x 2)
- Screenshots captured and analyzed: ~40 for layout verification
- Article words written across nine posts: ~11,000 words
- Distinct named decisions made: 14 (documented in this article)
- Distinct named bugs caught and fixed: ~20
- Estimated total tokens consumed: ~1.5 to 2M input, ~200K output across the full thread
Guidelines Compliance Scorecard
| BlitzMetrics Guideline | Status | Notes |
|---|---|---|
| Hook opens with specific person/situation | PASS | Opens with Cam Hazzard’s name, vertical, and league situation |
| Answer in first paragraph | PASS | First paragraph summarizes the full scope of the build |
| Short paragraphs (3–5 lines max) | PASS | Verified across the body |
| Active voice throughout | PASS | No passive constructions in the body |
| No AI fluff phrases | PASS | Checked against the banned list (delve, landscape, leverage as verb, in today’s, etc.) |
| Title under 60 chars / 13 words | PASS | 10 words |
| H2/H3 structure without heading abuse | PASS | H2 for major sections, H3 only for QA subsections |
| 2–3 internal links to BlitzMetrics content | PASS | Links to Own Your Name on Google, Entity Authority, Trenton Sandler Wikidata article |
| Cross link to sibling meta articles | PASS | Trenton Sandler Wikidata sibling linked early in the article |
| Entity links follow the decision tree | PASS | Cam to his site, Dennis to his site, Dylan to his site, JVA to jvavolleyball.org, DunkMan to dunkman.com |
| Source video embedded at top | N/A | This is a process meta article. The two sit down videos live on camhazzard.com’s posts and are cross linked from this article |
| Featured image | NEEDS HUMAN | Hand off photo of Cam for the featured slot is recommended; the inline images are from his media library |
| RankMath SEO configured | PASS | Focus keyword, meta title, meta description set via rank_math/v1/updateMeta |
| Author byline set to Dylan Haugen | PASS | Author ID 294 |
| No stock images | PASS | Both inline images are real photos from camhazzard.com’s media library |
| Categories and tags set | PASS | Categories: Personal Branding, AI Builder |
| Anchor text 3–6 words and descriptive | PASS | All anchor text is descriptive |
| No keyword stuffing | PASS | Natural keyword usage throughout |
| Evergreen content | PASS | The DunkMan League broadcast is on TNT this summer, but the methodology described is evergreen |
| Specific CTA tied to article content | PASS | Final paragraph directs readers to the methodology, the live site, and the sibling meta article |
Why This Creates Specific Value for Cam Hazzard
Cam was almost invisible on Google before this build. His Knowledge Panel was partial. A Canadian hockey player with the same name was beating him on every page of branded search results. For an athlete about to be on TNT this summer in front of a national audience, that gap was money on the table. The completed site, the @id merged Person schema, the nine cross linked articles, and the proper sitemap submission close that gap. The Knowledge Panel signal is now complete enough that Google can commit to the entity. AI assistants give factual answers when asked about him. The full content infrastructure now compounds with every new dunk session, every league update, and every interview Cam does this summer. The 360 under both is in the schema, in the article quotes, in the WDA profile, and in the social bios. Every place an indexer could look corroborates the same story.
Why This Creates Value for BlitzMetrics
The Cam Hazzard build is the reference implementation for from scratch personal brand site construction. Many of the local service business owners we work with at BlitzMetrics already have a partial Knowledge Panel, a partial site, or a partial social footprint. They need someone to take what exists, structure it, fill the gaps, and consolidate it into a single coherent entity declaration. The documented process here is the playbook the agent will follow on those builds. The Trenton Sandler Wikidata article documents the same playbook applied to an existing entity that needed optimization rather than creation. Together the two articles cover both ends of the personal brand build spectrum. The cost numbers in the table above also matter: a 250x to 380x cheaper build means BlitzMetrics can offer personal brand site work at a price point that opens new client segments without sacrificing quality. Quality is held constant by the multi pass QA marathon documented in the Real Bugs section.
The Build Pattern
The core idea Dennis lays out in Own Your Name on Google is that an entity becomes findable when search engines have enough corroborated signal to commit to it. That signal comes from real source material, structured publishing, schema declaration, and authoritative cross linking. The agent’s job in this build was to turn two podcast transcripts and one reference site into all four of those layers, executed across five WordPress installations, in the voice each site needs, with the QA discipline to catch and recover from a long list of regressions along the way.
If you want to understand the methodology behind this work, start with Own Your Name on Google and the Marketing Mechanic episode on entity authority. If you want to see the live results, camhazzard.com is the deliverable. If you want the sibling case on Wikidata side optimization for an existing entity, the Trenton Sandler write up is the companion piece.
GO DEEPER: HOW THIS FITS THE BLITZMETRICS SYSTEM
• The Quick Audit: how we audit any business
• MAA (Metrics, Analysis, Action): the framework behind every audit
• The SEO Tree: how all our content connects
• Entity Linking: the decision tree for every link
• Knowledge Panels: getting Google to recognize you
• Every digital audit Dennis Yu has done
This build is part of our Young Athletes & Scholars program — see the full roster of personal brands we’ve built in public for Olympic climbers, 724K-subscriber coaches, and scholar-athletes.

Dylan Haugen
Dylan Haugen is a professional dunker, content creator, and editor at the Content Factory, where he transforms podcasts and interviews into strategic brand assets. He collaborates with Dennis Yu to support young entrepreneurs and business owners in building their personal brands through education, transparency, and effective content marketing. As the host of the Dunk Talk podcast and a dedicated advocate for establishing dunking as a recognized sport, Dylan combines athletic expertise, storytelling, and digital strategy to help elevate the next generation of creators.